1. Transformer에서 self-attention의 의미
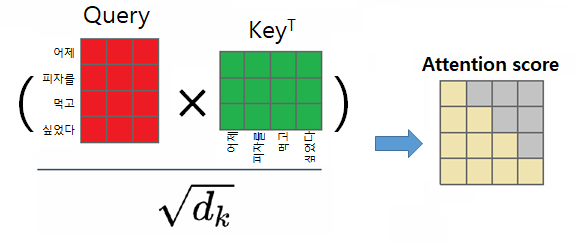
Self-attention은 자연어 텍스트와 같은 Sequential data를 처리하기 위한 Transformer layer에 있는 메커니즘입니다.
이를 통해 모델은 시퀀스의 중요한 부분에 집중하여 시퀀스의 각 요소에 대한 표현을 계산할 수 있습니다.
Attention score는 위 그림처럼, 2차원의 word vector에 대해 Matrix multiplication이 수행됩니다.
Word embedding이 잘 되어있다면, 비슷한 의미를 가지는 단어는 비슷한 Feature pattern을 보일 것입니다.
따라서, 같은 문장의 MatMul을 통해 만들어진 Attention score (Matrix)는 '유사도' 처럼 작동할 것입니다.
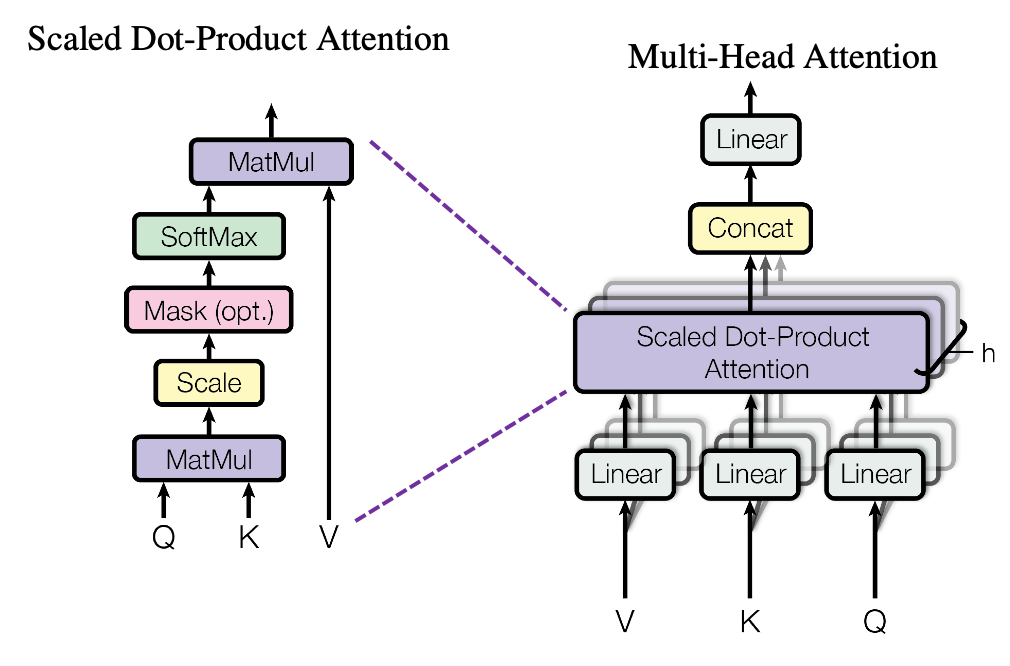
따라서, 위 그림의 좌측에 Q (Query), K (Key)의 MatMul 연산은 Attention Score (유사도) 를 구하는 과정이고,
이를 적절히 Scaling 및 Softmax를 통해 상대적으로 단어간의 유사도를 결정합니다.
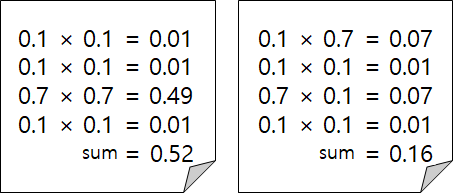
위 예는 두 단어의 similarity에 따른 Multiplication의 차이를 나타냅니다.
즉, 값이 높을 수록 유사하고, 값이 낮을수록 상이하다는 것을 알 수 있습니다.
자, 그러면 우리는 Attention score가 입력으로 사용된 문장 (Query, Key)의 Matrix-Multiplication으로 구해진 다는 것을 이해했습니다. 그리고 그 결과로 만들어진 Attention score가 Value와 곱해져서 중요한 단어에 attention이 가해진다는 것도 이해할 수 있습니다.
(대부분의 경우, Query, Key, Value는 주어진 Input sequence가 사용합니다. 가끔 Key가 다른 sequence로 사용될 수 있습니다.)
2. Attention score로부터 Importance 구하기
그러면, Attention score는 주어진 문장 길이의 제곱으로 구해진 Matrix 형태인데,
어떻게 단어별로 중요도를 구할 수 있을까? 라는 의문이 남습니다.
각 단어의 중요도를 계산하기 위해 입력 시퀀스의 다른 모든 단어에서 각 단어에 대한 Attention Score를 합산할 수 있습니다. (보통, 이는 한 단어의 embeding을 거친 feature vector를 의미할 수 있습니다)
한 단어에 대한 Attention score의 합산 결과는 중요성을 나타내는 단일 점수로 여겨질 수 있습니다.
다음은 코드의 예입니다.
import numpy as np
# assume `attention_scores` is a two-dimensional matrix with shape
# (batch_size, sequence_length, sequence_length)
# representing the attention scores for each pair of words in the input sequence
# sum the attention scores along the second dimension (the words being compared to)
# to obtain the total importance of each word
importance_scores = np.sum(attention_scores, axis=2)단일 Layer의 입장에서, Attention weight의 return shape는 다음과 같을 수 있습니다.
(batch_size, sequence_length, sequence_length)
하지만, num_heads를 고려하면, 4-dim 으로 return될 수 있습니다.
(batch_size, num_heads, sequence_length, sequence_length)
3. 예제 구현해보기
- 패키지 로드
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
- 데이터 로드
vocab_size = 20000 # Only consider the top 20k words
maxlen = 200 # Only consider the first 200 words of each movie review
word_index = tf.keras.datasets.imdb.get_word_index() # get {word : index}
index_word = {v : k for k,v in word_index.items()} # get {index : word}
(x_train, y_train), (x_valid, y_valid) = tf.keras.datasets.imdb.load_data(num_words=vocab_size)
x_train = tf.keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_valid = tf.keras.preprocessing.sequence.pad_sequences(x_valid, maxlen=maxlen)
# token된 데이터 영문으로 출력해보기
DataIndex = 5
" ".join([index_word[idx] for idx in x_train[DataIndex]]), y_train[DataIndex]
- 간단한 모델 구현
EmbeddingDim = 128
WordLen = 200
inputs = tf.keras.layers.Input(shape=(WordLen,))
embedding_layer = layers.Embedding(input_dim=200, output_dim=EmbeddingDim)(inputs)
attn_output, weight = layers.MultiHeadAttention(num_heads=5, key_dim=4, use_bias=True)(
embedding_layer, embedding_layer, return_attention_scores=True)
#attn_output을 활용하여 final output까지 작성은 생략
Model_withWeight = tf.keras.Model(inputs=inputs, outputs=[weight])
- 예측 및 attention weight 가져오기
attention_weights = Model_withWeight.predict(x_valid[:2])
attention_weights.shape1/1 [==============================] - 0s 16ms/step
(2, 5, 200, 200)2: input 데이터의 batch 크기
5: num_heads
200: length of sequence1
200: length of sequence2
- 최종 Attention score 구하기
importance_scores = np.sum(attention_weights, axis=3)
'Programing > Python programming' 카테고리의 다른 글
| Sklearn - PolynomialFeatures (0) | 2023.05.01 |
|---|---|
| tf.keras로 Embedding layer 뜯어보기, 구현해보기 (0) | 2023.03.08 |
| Python for loop, map, Filter, Reduce 정리 (0) | 2022.12.27 |
| tf.Keras 기본코드로 이해하는 Transformer (0) | 2022.10.21 |
| Deep Attention-Sampling Models: 큰 이미지의 End-to-end 학습 (0) | 2019.08.10 |