뭔가 Transformer는 참 항상 어렵게 느껴졌었다.
왜이렇게 강의들이나 문헌들이 어렵게 적혀있는지,
Key, Query, Value는 도대체 어디서 튀어나오는 것인지 명확하게 이해가 안됐다.
내가 이해할 수 있도록 글을 쓰면, 독자분들도 쉽게 이해할 수 있지 않을까?
라는 마음으로 이 글을 한번 써보도록 한다.
코드는 모델링을 기준으로 상세하게 덧붙여 가며 설명한다.
0. Library & 예제 데이터 준비
- Tensorflow Keras, Library Load
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
- IMDB Data load
https://www.tensorflow.org/api_docs/python/tf/keras/datasets/imdb/load_data
tf.keras.datasets.imdb.load_data | TensorFlow v2.10.0
Loads the [IMDB dataset](https://ai.stanford.edu/~amaas/data/sentiment/).
www.tensorflow.org
- 데이터 불러오기
vocab_size = 20000 # Only consider the top 20k words
maxlen = 200 # Only consider the first 200 words of each movie review
(x_train, y_train), (x_val, y_val) = keras.datasets.imdb.load_data(num_words=vocab_size)
print(len(x_train), "Training sequences")
print(len(x_val), "Validation sequences")
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_val = keras.preprocessing.sequence.pad_sequences(x_val, maxlen=maxlen)각각 단어 하나마다 모두 정수인코딩 되어 숫자로 나열된다.
따라서 각 문장마다 데이터의 길이가 다르다.
이를 해결하기 위에, 앞에 0을 추가하여 모두 똑같은 길이로 만드는 것이 바로 pad_sequences 함수의 역할이다.
(max_len 만큼으로 만들어줌)
(padding으로 인해 앞에 0이 추가된 모습)

1. Token and Position Embedding
- Embedding이란?
inputs = layers.Input(shape=(200,))
x = layers.Embedding(input_dim=128, output_dim=32)(inputs)
tf.keras.Model(inputs=inputs, outputs=x).summary()Model: "model_13"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_12 (InputLayer) [(None, 200)] 0
embedding_19 (Embedding) (None, 200, 32) 4096
=================================================================
Total params: 4,096
Trainable params: 4,096
Non-trainable params: 0
_________________________________________________________________input으로 들어오는 것은 200개의 단어가 200개의 정수로 인코딩된 데이터이다.
이를 embedding을 하게 되면, 200 * 32 의 feature로 만들어지는데,
즉 200개의 숫자로된 데이터 하나 하나가 32개의 feature로 증폭이 되는것을 의미한다.
위 코드에서 input_dim=128, output_dim=32 인데,
단어 하나마다 128개의 weight를 곱하여 하나의 값으로 합치는 것을 32번 하라는 뜻이다.
따라서 총 128*32 = 4096개의 weight가 있으며, 이를 모든 200개의 단어에 수행하게 된다.

Embedding은 위 figure로 보듯, 단어 하나를 매우 높은 dimension으로 projection 하는 것을 의미한다.
여기에 Positional encoding이란 것은, 각 단어마다 위치정보를 알려주는 것을 뜻한다.
inputs = layers.Input(shape=(200,))
x = layers.Embedding(input_dim=128, output_dim=32)(inputs)
positions = tf.range(start=0, limit=200, delta=1)
positions = layers.Embedding(input_dim=200, output_dim=32)(positions)
embedding_layer = x+positions위 두줄은 단순 embedding, 아래 positions는 각 단어의 위치에 따른 index값을 주고,
index값을 emedding 하여 feature를 추출한 후,
단어 embedding 결과 + 위치 embedding 결과를 합한다.
따라서, 단어와 위치정보를 결합한 feature를 추출할 수 있다.
(참고로 positions에 상수 200개가 들어오고, 200*32개의 feature로 추출하므로,
6400개의 parameter가 존재한다고 볼수있긴 하다)
2. Multi-head Attention
Multi-head attention을 이해하기 위해서, 진짜 가장 가장 쉬운 layer를 구축하여 이해해보자.
일단 아래 그림을 보면, V, K, Q가 있다.
이것은 Value, Key, Query의 약자인데,
위에서 encoding 된 feature matrix에 대하여,
독립적인 weight에 해당하는 Wv, Wk, Wq를 곱해서 만들어진 결과에 불과한 것이다.
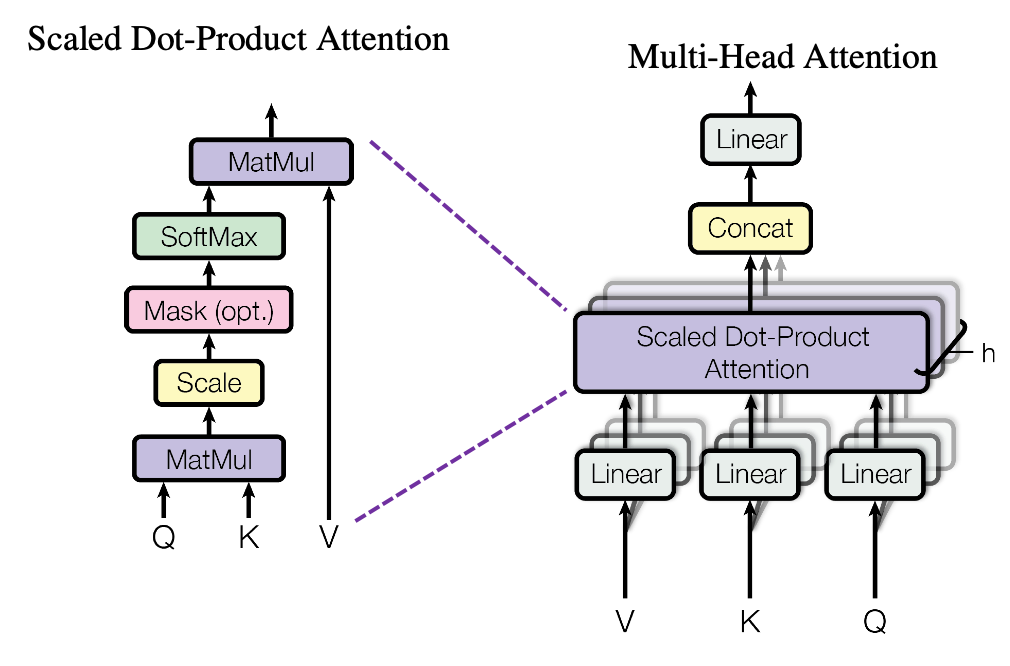
- (위 그림에서 Scaled Dot-Production 전까지)
embedding layer로부터 나온 Matrix에 대하여,
서로 독립적인 Wv, Wk, Wq 라는 weight를 곱해줘서 V, K, Q를 구한 후
Scaled Dot-Production 이라는 것을 통해 V, K, Q를 하나로 합쳐준 후
또 weight를 주어 output을 내뱉는 것으로 구성되어있다.
따라서, weight가 부여되는 layer는 4개로 생각할 수 있다.
EmbeddingDim = 5
WordLen = 5
inputs = layers.Input(shape=(WordLen,))
positions = tf.range(start=0, limit=WordLen, delta=1)
positions = layers.Embedding(input_dim=WordLen, output_dim=EmbeddingDim)(positions)
x = layers.Embedding(input_dim=200, output_dim=EmbeddingDim)(inputs)
embedding_layer = x+positions
attn_output = layers.MultiHeadAttention(num_heads=1, key_dim=1, use_bias=False)(embedding_layer, embedding_layer)
tf.keras.Model(inputs=inputs, outputs=attn_output).summary()
Model: "model_74"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_65 (InputLayer) [(None, 5)] 0 []
embedding_129 (Embedding) (None, 5, 5) 1000 ['input_65[0][0]']
tf.__operators__.add_57 (TFOpL (None, 5, 5) 0 ['embedding_129[0][0]']
ambda)
multi_head_attention_56 (Multi (None, 5, 5) 20 ['tf.__operators__.add_57[0][0]',
HeadAttention) 'tf.__operators__.add_57[0][0]']
==================================================================================================
Total params: 1,020
Trainable params: 1,020
Non-trainable params: 0
__________________________________________________________________________________________________
위 모델은 input dimension을 매우 축소해서, embedding 결과로부터 얻는 output을 5*5로 바꾸어 예제를 구성해보았다.
Embedding dimension이 5이므로, output dimension은 wordLength * 5가 된다.
따라서 단어 하나당 5개의 feature가 생성되므로, 이들과 곱해주기 위한 layer를 만들기 위해서
(Query, Key, Value를 만들어주기 위한 weight) weight가 각 5개씩 필요하다.
그리고 Query, Key, Value에 대한 Scaled dot-Product attention이 수행된 이후 concat한 뒤,
또다시 layer 하나를 지나치게 되는데, 이때 같은 weight dimension이 필요하게 된다.
따라서 parameter가 20개가 되는 것이다.
20 = 4 (Number of weights) * 5 (Embedding dimension)
Model = tf.keras.Model(inputs=inputs, outputs=attn_output)
[Weights.shape for Weights in Model.get_weights()]
[(200, 5), (5, 1, 1), (5, 1, 1), (5, 1, 1), (1, 1, 5)]
앞에 200, 5는 embedding layer의 weight인 1000개의 parameter를 뜻하며,
그 다음 (5, 1, 1), (5, 1, 1), (5, 1, 1)는 Query, Key, Value에 대한 weight,
그리고 마지막 (1, 1, 5)는 concat 이후의 weight를 의미한다.
(dot production 내부에서 transpose 되기 때문에 순서가 뒤집힌다.)
MultiHeadAttention layer에 num_heads와 key_dim를 바꿔주면 어떻게 될까?
num_heads = 2
key_dim = 3
으로 설정해주었다.
EmbeddingDim = 5
WordLen = 5
inputs = layers.Input(shape=(WordLen,))
positions = tf.range(start=0, limit=WordLen, delta=1)
positions = layers.Embedding(input_dim=WordLen, output_dim=EmbeddingDim)(positions)
x = layers.Embedding(input_dim=200, output_dim=EmbeddingDim)(inputs)
embedding_layer = x+positions
attn_output = layers.MultiHeadAttention(num_heads=2, key_dim=3, use_bias=False)(embedding_layer, embedding_layer)
Model = tf.keras.Model(inputs=inputs, outputs=attn_output)
Model.summary()
[Weights.shape for Weights in Model.get_weights()]Model: "model_100"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_80 (InputLayer) [(None, 5)] 0 []
embedding_159 (Embedding) (None, 5, 5) 1000 ['input_80[0][0]']
tf.__operators__.add_72 (TFOpL (None, 5, 5) 0 ['embedding_159[0][0]']
ambda)
multi_head_attention_70 (Multi (None, 5, 5) 120 ['tf.__operators__.add_72[0][0]',
HeadAttention) 'tf.__operators__.add_72[0][0]']
==================================================================================================
Total params: 1,120
Trainable params: 1,120
Non-trainable params: 0
__________________________________________________________________________________________________
[(200, 5), (5, 2, 3), (5, 2, 3), (5, 2, 3), (2, 3, 5)]각 모든 layer의 파라미터 수는
(Embedding features, Number of heads, Key dimension) 으로 변화하게 된다.
use_bias=True 로 하게 되면, 중간에 상수가 몇가지 더해지는 것을 확인할 수 있다.
다만 지금 글에서는 bias까지는 다루지 않는다.)
3. Scaled dot Product Attention
이제 모든 파라미터가 몇개가 왜 존재하며, 어떻게 주어지고, 어떻게 연산되는지 알았으니
Scaled dot Production Attention만 이해하면, Transformer는 끝이 난다.
Query, Key, Value 등은 컨셉일 뿐이므로, 아래 공식을 아주 간단하게만 보자.
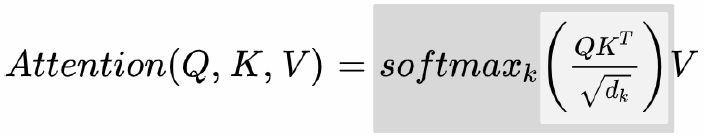
위 Attention 공식에서, 우리가 가장 주의깊게 봐야 할 것은 바로 QK^T 이다.

Embedding된 같은 text에 서로 다른 weight가 곱해진 scaled된 두 행렬 (Query와 Key)은
한쪽을 Transpose 한 이후에 곱연산을 함으로써, 각 단어의 Similarity를 구할 수 있다.
왜냐하면, 같은 의미의 단어일 수록 embedding 된 feature의 값들이 비슷하므로 서로 높은 값끼리 곱해지고,
의미가 먼 단어일 수록 서로 낮은 값들이 곱해진다.
(물론 Query, Key를 만들기 위해 곱해지는 feature에 의해 약간의 변화가 존재하지만)

따라서 위 공식을 간단하게 생각해보면,
단어들의 유사도 (Similarity)와 같은 역할을 하는 Attention Score를 구하고, 이를 Value에 곱하는 꼴이 된다.
이게 바로 Single-Head attention의 역할이다.
이 때, num_heads는 이 attention matrix를 만드는 수행을 몇번 할 것이냐를 의미하게 된다.
4. Final Classification model
마지막으로, embedding 된 feature에 대해 MultiHead Attention을 통과 한 후,
classification을 수행하는 모델을 구현해 보자.
EmbeddingDim = 128
WordLen = 200
inputs = layers.Input(shape=(WordLen,))
positions = tf.range(start=0, limit=WordLen, delta=1)
positions = layers.Embedding(input_dim=WordLen, output_dim=EmbeddingDim)(positions)
x = layers.Embedding(input_dim=200, output_dim=EmbeddingDim)(inputs)
embedding_layer = x+positions
attn_output = layers.MultiHeadAttention(num_heads=1, key_dim=2, use_bias=True)(embedding_layer, embedding_layer)
x = layers.GlobalAveragePooling1D()(attn_output)
outputs = layers.Dense(2, activation="softmax")(x)
Model = tf.keras.Model(inputs=inputs, outputs=outputs)
Model.summary()__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_87 (InputLayer) [(None, 200)] 0 []
embedding_173 (Embedding) (None, 200, 128) 25600 ['input_87[0][0]']
tf.__operators__.add_79 (TFOpL (None, 200, 128) 0 ['embedding_173[0][0]']
ambda)
multi_head_attention_77 (Multi (None, 200, 128) 1158 ['tf.__operators__.add_79[0][0]',
HeadAttention) 'tf.__operators__.add_79[0][0]']
global_average_pooling1d_3 (Gl (None, 128) 0 ['multi_head_attention_77[0][0]']
obalAveragePooling1D)
dense_14 (Dense) (None, 2) 258 ['global_average_pooling1d_3[0][0
]']
==================================================================================================
Total params: 27,016
Trainable params: 27,016
Non-trainable params: 0
__________________________________________________________________________________________________
Multi-head Attention이 지나간 output은 Embedding layer의 output과 동일하므로,
1D Gloval Average pooling을 통해 Vector화 할 수 있다.
따라서 이를 Fully-connected Binary classification layer를 통과시켜주면,
classification model 작성 끝
'Programing > Python programming' 카테고리의 다른 글
| tf.keras에서 Transformer의 self attention 및 중요도 (0) | 2023.02.05 |
|---|---|
| Python for loop, map, Filter, Reduce 정리 (0) | 2022.12.27 |
| Deep Attention-Sampling Models: 큰 이미지의 End-to-end 학습 (0) | 2019.08.10 |
| Multi-view image deep learing with CNN-LSTM (0) | 2019.04.03 |
| scikit-image 설치 에러 Microsoft visual c++ 14.0 required (1) | 2018.01.26 |