- Self-supervised learning (자기 지도 학습)
Label이 없는 데이터를 활용하여 모델을 학습시키는 방법
- Contrastive learning (대조 학습)
Self-supervised learning 중의 하나로, 양의 쌍 (유사한 샘플)과 음의 쌍 (비슷하지 않은 샘플) 을 사용해서 데이터 샘플 간의 유사성을 학습하는 방식
Siamese network 같은 기본적인 contrastive learing은 매우 이해하기 쉬운데, 예를 들면
- Input으로 주어진 2개의 이미지 (A, B)가 동일한 Label을 가졌느냐, 서로 다른 이미지냐
- 혹은 A를 Augmentation (회전, 대조, flip, Crop 등을 활용한) A' 를 생성하여
(A, A'): 양의 쌍
(A, B): 음의 쌍
으로 네트워크를 학습하는 방식이다.

Siamese Network: 두 개의 입력 이미지를 동일한 네트워크를 통해 처리. 두 이미지를 각각 임베딩으로 변환하고, 이 임베딩들 사이의 거리 또는 유사도를 계산 (동일한 class: Positive pair, 다른 class: Negative pair)
SimCLR: 하나의 이미지에서 두 개의 다른 증강 버전을 생성. 이 두 이미지는 동일한 네트워크를 통과하여 각각의 임베딩을 생성하고, 이 임베딩들 사이의 유사도를 계산. (하나의 이미지에서 증강: Positive pair, 다른 이미지: Negative pair)
Self-Supervised Learning without Negative Sampling
BYOL, SimSiam, MoCo, SwAV, Barlow Twins 등 negative sampling을 활용하지 않는 다양한 메소드들도 존재

DINO 역시 Negative sampling 없이, Knowledge distilation에서 착안한 self-distillation 이라는 방식을 사용한다.
- Knowledge distilation
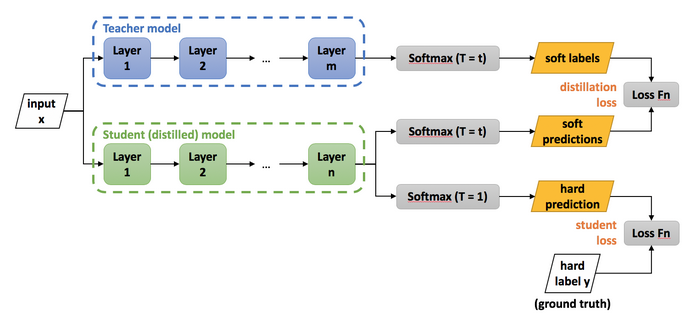
Knowledge distilation은 주로 많은 수의 Parameter를 가진 모델을 학습한 후, 모델을 경량화 하기 위해 사용되는 기법이다.
위 그림에서, Teacher model을 미리 학습한 후, 차후에 Student model을 학습할 때 실제 학습데이터의 Ground truth label을 loss로 주는것 뿐 만 아니라, Teacher model이 내뱉는 output 또한 soft-label로 제공하여 student model을 학습한다.
이 때, 적은 수의 파라미터를 가진 Student model이라 할 지라도, teacher model에 버금가는 성능을 뽑아낼 수 있다.
아무튼, DINO는 self-supervised learning + Knowledge distiliation 이다.
- DINO의 추상적인 summary
간단하게 DINO를 이해하자면, DINO는 이미지에서 여러 patch를 추출하는데, 주로 두 가지 유형의 patch를 사용한다.
- 전체 이미지의 전반적인 정보와 컨텍스트를 포착하는 큰 patch, 즉 'global view'
- 이미지의 특정 지역 또는 세부 정보를 포착하는 작은 patch, 즉 'local view'
이 두 종류의 patch는 각각 다른 네트워크 (보통 'student'와 'teacher'라고 불림)를 통과한다.
학습 과정에서는 student 네트워크가 teacher 네트워크의 출력을 따라하도록 파라미터를 업데이트 한다.
Local view와 Global view에서 동일한 feature를 출력하도록 함으로써, 모델이 이미지의 세부적인 txture를 인식하게 하는 방법이다.

위 그림은 DINO 공식 github에서 제공하는 이미지인데 (실제로 gif 애니메이션),
local view를 보는 student와 global view를 보는 teacher가 동일한 feature를 내뱉도록 학습하는 방식으로 이해할 수 있다.
다만, DINO를 처음 보는 분이시면, 다음의 의문을 가질 수 있다.
1) teacher가 쓰레가값을 내뱉는데, 그걸 student가 학습해서 어쩌자는거지?
2) 둘다 똑같은 상수만 출력하면 어쩌지?
3) 이 방식이 어째서 배경을 제외한, 주요 물체를 주요하게 인식할 수 있는거지?
DINO: Self-Distilation with no Labels
1. INPUT data의 처리
이미지의 shape가 (224, 224) 로 가정할 때, 2가지의 category로 patch를 만든다.
- Gloval view: 전체 이미지의 50% 이상을 cover할 수 있는 큰 patch
- Local view: 이미지의 50% 이하를 cover할 수 있는 작은 patch. # 이 논문에선 (96, 96)

Default로는 2개의 global view를 생성하고, 8개의 local view를 생성한다.
Local, Global View에 따라 조금 다르게 augmentation을 추가적으로 수행한다.
(Flip, ColorJitter, GaussianBlur, Solarization)
2. Model structure

이 논문은 개인적인 견해로, 3가지의 part로 나눌 수 있다.
1) ① ~ ③ 까지의 forward step.
앞서 1번의 'Input 데이터 처리' 에서 언급한 crop을 수행하는 augmentation을 거쳐, global view와 local view에 해당하는 이미지들을 생성한다. teacher에는 오직 global view만 입력으로 들어가며, student는 모든 입력을 받는다.
(default 값으로, global view는 2장, local view는 8장이므로 student는 대부분 local view가 들어간다고 생각할 수 있다)
이제 생성된 local view를 x1, global view를 x2라고 가정하고, 모델의 input으로 사용한다.
student model은 gs라고 가정하고, teacher model은 gt라고 가정한다.
Student model의 output: gs(x1)
Teacher model의 output: gt(x2)
각 두가지 모델 gs, gt로부터 출력된 데이터 p1, p2는 vector형태를 가지는 representation이 된다.
global view, local view에 따라 image size가 달라질 수 있는데, 모델 (gs, gt)에 input으로 들어갈 때, image size를 resize 해주는 것이 아니고, back-bone이 ViT 이기 때문에, 단순히 서로 다른 수의 patch를 만들어낼 뿐 이미지 크기는 문제가 없다. MultiCropWrapper를 사용한다. 이는 ViT 에서 이미지를 patchify 하듯 작은 이미지는 작은 수의 patch로 쪼개서 feature를 뽑아주는 것 뿐이다.
기본 vit_small의 embed_dim은 386이므로, 한장의 이미지당 386개의 feature가 추출될 것이다. 따라서,
student에는 2장의 global view, 8장의 local view가 들어가므로, 최종적으로 (10, 386) 을 output으로 한다.
teacher에는 2장의 global view만이 들어가므로, 최종적으로 (2, 386)을 output으로 한다.
loss는 student에서 나온 하나의 output과, teacher에서 나온 하나의 output을 조합하여 학습되는데, 따라서 위의 예제로 10*2, 총 20번의 loss가 계산될 것이다.
* Sharpening
386개의 feature를 내뱉는 모델에서, default로 0.1로 나눠주는 작업을 수행한다. (즉 10을 곱한다)
# student_out = student_output / self.student_temp
이렇게 되면, softmax의 output에서 높은 값은 더 높게 바꿔주는 것인데, 값이 모호하거나 부드러운 경우 feature의 분포를 더욱 뾰족하게 만들어줌으로써 더 명확한 gradient를 주어 학습속도를 빠르게 하고, 학습의 안정성을 증가시킵니다.
3. 모델의 학습

- Student model은 Teacher의 output을 label로 하여 cross-entropy loss로 학습된다.
첫번째로 업데이트 되는 parameter는 Student 모델 gs이다.
loss는 p2 * log(p1) 형태로 표현되어있다.
②student output인 (10, 386)과, ③teacher output인 (2, 386) 중 하나씩 골라서, teacher를 label로 하여금 cross-entropy를 계산하여 최종 loss를 얻는다.
참고로 원래 cross entropy의 p2는 Label을 나타내고, p1이 predicted value를 나타낸다.
Cross entropy H(p1,p2)=−∑p2*log(p1)
여기서 의문점이 들 수 있는 것은, Label이 없는데 뭘 업데이트 하는가?
=> teacher에서 output으로 뱉는 p2를 label처럼 학습한다.
student가 보는 local view와, teacher가 보는 global view가 일치한다는 걸 통해 student 모델은 파라미터를 업데이트 한다.
* Sharpening, Centering
cross-entropy loss를 계산하기 전에,
student의 output은 sharpening을 거쳐 output이 생성되며,
teacher는 centering + sharpening을 모두 수행한다.
*Centering: DINO에서는 "centering"이라는 추가적인 정규화 과정을 거침. 이는 전체 학습 데이터셋에 대한 teacher의 평균 출력 값을 계산하고, 각각의 teacher 출력에서 이 평균 값을 뺌. 이렇게 하면, teacher의 출력이 0 주위로 중앙 집중되게 되고, 이 과정은 모델이 일관된 방향으로 바이어스되는 것을 방지하고, 학습 동안의 안정성을 증가시킴
실제 코드는 다음과 같다.
- Student의 sharpening
student_out = student_output / self.student_temp
- Teacher의 sharpening + centering
teacher_out = F.softmax((teacher_output - self.center) / temp, dim=-1)
(참고로 center는 매번 batch의 center를 직접 구하는건 아니고, momentum을 주어 이전 batch의 center에서부터 center_momentum % 만큼 움직이도록 구현되어있음)
- Teacher model은 Student의 parameter의 가중평균을 통해 학습된다.
teacher 모델은 student의 파라미터와 weighted 평균을 통해 파라미터를 업데이트 한다.
논문의 수도코드는 다음과 같다. (그림의 ⑤)
gt.params = lambda * gt.params + (1-lambda) * gs.params
- Summary
DINO는 Knowledge distillation을 활용한 self-supervised learning 메소드이다.
DINO는 Local view를 주로 보는 student와, Global view를 보는 teacher의 feature를 비슷하게 출력하게 함으로써, 이미지 전체적인 texture를 세부적으로 관찰할 수 있게 해준다.
본문의 처음에서 언급했던 '모두 같은 숫자를 내뱉으면 무조건 student의 loss는 0으로 수렴할텐데? 라는 의문이 있었다.
Self-supervised learning에서 "collapse"는 모델이 항상 동일한 출력을 생성하는 현상을 의미한다. contrastive learning에서 일반적으로 나타나는 현상인데, 양성쌍과 음성쌍의 차이를 극대화 하는 대신에, 모든 출력을 동일하게 만들어서 loss를 떨어뜨리려고 하는 경향이다.
Collapse 문제는 contrastive learning에서 매우 해결하기 어려운 문제였는데, 기존 문헌들에서는 clustering constraints, Multi-layer, batch normalization 등을 활용하여 이 문제를 해결하기 위해 노력했었다. 하지만 DINO는 Sharpening과 Centering을 활용하여 이 문제를 해결할 수 있었다. (DINO 논문의 Avoiding collapse, 참조)
'Major Study. > Journal study' 카테고리의 다른 글
| 지식펜 강의 - 연구계획서 작성 방법 (0) | 2016.04.15 |
|---|---|
| VEGF-A Expression correlates with TP53 mutations in NSCLC (0) | 2015.09.27 |
| Microsatellite 반복서열의 기능, 기작 및 특성 (1) | 2015.07.28 |
| Gene expression data and Survival analysis (0) | 2015.07.16 |
| Integrating genomic and transcriptomic and functional data (0) | 2015.07.11 |